スキップしてメイン コンテンツに移動
検索
このブログを検索
日々是精進。
日々ネットで調べたり、付箋に書き留めたものをアップしています。子育てで中断しながらも、年に数回投稿しています。皆様の恩恵に感謝しつつ。
ページ
ホーム
もっと見る…
投稿
2010の投稿を表示しています
すべて表示
12月 19, 2010
QlikViewメモ
12月 15, 2010
Agile Day4に参加させていただきました。
11月 29, 2010
Redmine Importerを使わせていただきました。
11月 15, 2010
Hudson勉強会に行ってきました。(20101112)
11月 15, 2010
HudsonからSVNリポジトリへのアクセス
4月 09, 2010
Svnsyncでリポジトリの同期 (Remote To Remote)
3月 11, 2010
RPMでhudsonをインストール
2月 16, 2010
iw.rotatezlogs
2月 04, 2010
SetEnvIf を使うんだけど…。
2月 01, 2010
blobstorageの中身
1月 27, 2010
Varnishのタイムアウト
1月 12, 2010
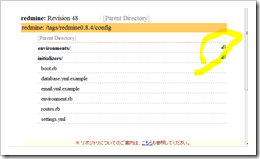
リポジトリブラウズに、SVNIndexXSLTを利用する
1月 07, 2010
Ploneおぼえがき
1月 05, 2010
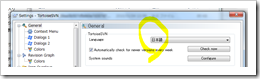
TortoiseSVNのインストール / 設定
新しい投稿
前の投稿
ホーム