スキップしてメイン コンテンツに移動
検索
このブログを検索
日々是精進。
日々ネットで調べたり、付箋に書き留めたものをアップしています。子育てで中断しながらも、年に数回投稿しています。皆様の恩恵に感謝しつつ。
ページ
ホーム
もっと見る…
投稿
2012の投稿を表示しています
すべて表示
12月 21, 2012
RubyMine + Jenkins Control Plugin
12月 18, 2012
#jbugj RubyMineがとても良い件。
12月 13, 2012
チケットを復旧する
12月 03, 2012
TortoiseHgインストール (Mac編)
11月 30, 2012
多段SSHでRDP
11月 29, 2012
MacBook生活始めました。
11月 09, 2012
JenkinsからYammerに通知をしてみました。
10月 22, 2012
Jenkins勉強会#6でお話させていただきました。(スピーカー体験編)
10月 03, 2012
Oracle Application Testing Suiteハンズオンセミナー
9月 20, 2012
NetBeansがうまく起動しないとき
7月 14, 2012
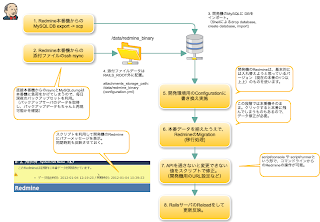
Redmineのプラグインのポーティングメモ (to Redmine2.0.x)
7月 12, 2012
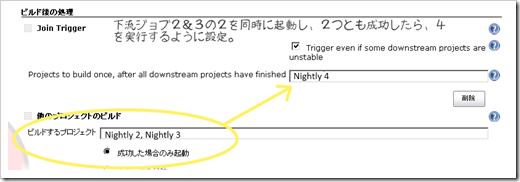
Join Pluginを試す&Build pipline Pluginで表示してみる
7月 06, 2012
運用ネタ: チケット削除しちゃったんですが…。
6月 25, 2012
Jenkinsのプラグインのバイナリ(*.hpi) を手動で追加する場合
5月 26, 2012
nginxの設定調整
5月 02, 2012
まあ飲めや、なプラグイン
5月 01, 2012
Bitbucketにお引越しさせてみた。
4月 19, 2012
Redmine1.4の準備 / 開発環境のメモ
3月 14, 2012
Redmine REST API - 関連チケット、添付ファイル込み
2月 24, 2012
第5回 Jenkins勉強会に参加させていただきました
2月 03, 2012
バージョンアップの際に忘れていた..。
1月 30, 2012
Nginxの設定メモ
1月 30, 2012
git / github 覚え書き
1月 25, 2012
Redmine勉強会 #2に参加 + 初LTしてきました。
新しい投稿
前の投稿
ホーム